Latent GOLD 5.1 日本語版
米国Statistical Innovations社が開発した潜在クラス分析用の統計ソフトの日本語版です。3種類の異なったモデル構造の推定モジュールを含んでいます。潜在クラス分析モデルは潜在クラスモデルをベースにしたクラスタ分析が行えます。離散因子モデルはカテゴリ変数の測定とエラー分類が可能です。日本語のデータを扱うことが可能です。

-
 T6O0007
Basic(1年)
T6O0007
Basic(1年)
-
 ¥ 68,200
本体価格 ¥ 62,000
¥ 68,200
本体価格 ¥ 62,000



-
T6O0006
Basic(永年)
-
¥ 163,900
本体価格 ¥ 149,000
-
T6O000D
Basic + Choice(1年)
-
¥ 136,400
本体価格 ¥ 124,000
-
T6O000C
Basic + Choice(永年)
-
¥ 328,900
本体価格 ¥ 299,000
-
T6O000K
Basic + Adv/Syntax(1年)
-
¥ 95,700
本体価格 ¥ 87,000
-
T6O000J
Basic + Adv/Syntax(永年)
-
¥ 218,900
本体価格 ¥ 199,000
-
T6O000R
Basic + Choice + Adv/Syntax(1年)
-
¥ 163,900
本体価格 ¥ 149,000
-
T6O000Q
Basic + Choice + Adv/Syntax(永年)
-
¥ 383,900
本体価格 ¥ 349,000
価格は予告なく変更される場合があります。
インストール条件については、各ソフトウェアの利用許諾書を必ずご覧ください。
![]() マークが付いている商品のご注文はWEBからは出来ません。詳しくはこちらをご覧ください。
マークが付いている商品のご注文はWEBからは出来ません。詳しくはこちらをご覧ください。
- 製品特徴
潜在クラス分析とは
潜在クラス分析は、個々に蓄積された数値である・なしに関わらない膨大なデータ(BigData)の中から、カテゴリー変数間の関係をもとに観測対象ごとにクラス分けを行う手法で、属する1つのグループを決めるのではなく、複数のグループに属する曖昧さを認めるものです。
Latent GOLDでは、カテゴリー変数だけではなく離散的なカウント変数や連続変数も取り扱うことが可能です。潜在クラス分析は母集団が異質集団の混合であると想定していることから、マーケティング分野でのセグメンテーションからターゲティングのためのツールとして広く活用されています。
また、医療分野をはじめとしたさまざまな分野で利用が広がっています。今後BigDataの活用が拡大するにつれ、ますます注目される分析手法といえます。Latent GOLDの機能と特長
Latent GOLDは、基本セットのBasic(必須)とChoice、Advanced/Syntaxという2つのアドオンとその組み合わせで構成されています。
Basic【必須モジュール】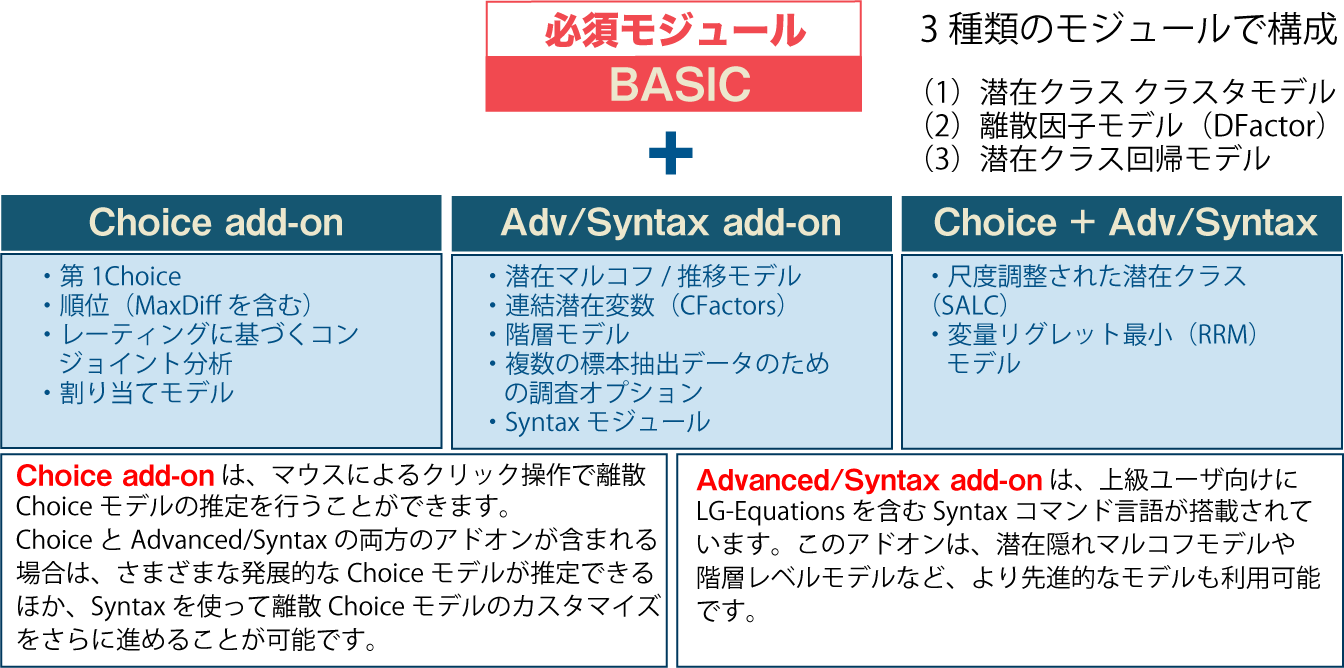
Choice【アドオン】LC Cluster
Latent GOLDのクラスタモジュールは、潜在クラスモデルに基づくクラスタ分析の最先端技術を提供します。 潜在クラスは、観察できない(潜在的な)サブグループまたはセグメントです。 同じ潜在クラス内のケースは特定の基準(変数)で同種ですが、異なる潜在クラスのケースは特定の重要な点で互いに異なります。従来の潜在クラスモデルは、カテゴリ変数を処理するための手法で、名義および順序尺度、連続、カウント、またはこれらの任意の組み合わせである変数群に対応することができます。離散因子(DFactor)
DFactorモデルは、可変減少または順序的なattitudinal尺度の定義によく使用されます。これには、共通の変動要因を共有する変数をグループ化する1つ以上のDFactorが含まれています。 各DFactorは2値型(デフォルトのオプション)または3つ以上の順序付けられたレベル(順序付けられた潜在クラス)で構成されています。
DFactorモジュールの利点
・すぐに解釈可能で、ローテーションは必要なし
・因子は序数であり、連続ではないと仮定
・因子スコアを推定するための追加の仮定は必要なし
・観測される変数は、名義および順序尺度、連続、カウント、これらの任意の組み合わせLCの回帰と成長
回帰モデルは、同種集団における予測変数の関数として従属変数を予測するために使用されます。 Latent GOLDは、カテゴリの潜在変数を含めることによって、異なる集団の回帰モデルを推定可能です。 この潜在変数の各カテゴリは、同一の回帰係数を有する均質な部分母集団(セグメント)を表します。 有益な診断統計を使用して、複数のモデルが必要かどうかを調べることができます。 各ケースには、成長曲線モデルまたはイベントヒストリモデルを推定するために、複数のレコード(繰り返し測定による回帰)が含まれている場合があります。 適切なモデルは、従属変数の尺度タイプに従って推定されます
・連続 – 線形回帰(正規分布残差を使用)
・2値型(名義、順序、または2項数として指定)
– 2項ロジスティック回帰
・名義(2レベル以上)– 多項ロジスティック回帰
・順序(2レベル以上の順序)
– 隣接カテゴリー序列ロジスティック回帰
・カウント:対数ポアソン回帰
・二項カウント:二項ロジスティック回帰モデル
予測変数(predictors)を使用して各クラスの回帰モデルを推定することに加え、共変量を指定してクラスの意味付けを分かりやすくしたり、適切な潜在クラスへのケースの分類を行うことができます。ステップ3 モジュール
潜在クラス分析を実行した後、クラスメンバーシップと外部変数の関係を調べることができます。
一般的な3段階のアプローチは、まず 潜在クラスモデルを推定し(ステップ1)、 次に、事後クラス帰属確率を用いて潜在クラスにケースを割り当て(ステップ2)、 その後、割り当てられたクラス帰属と外部変数との関連性を調べます(ステップ3)。
ステップ2では、個体を潜在クラスに割り当てる際に、誤分類を評価します。 外部変数との関連性の推定値は、偏りを防ぐために誤分類に対して補正する必要があります(Bolck、Croon、and Hagenaars、2004)。
ステップ3モジュールは、2つのバイアス調整手順を実装しています(Vermunt、2010)。クラス帰属を予測する外部変数(共変量オプション)またはクラス帰属によって予測される外部変数(従属オプション)とともに使用できます。
これらの2つのタイプの外部変数は、付随変数および外部目的変数とも称されます。 また、ケースを潜在クラスに割り当てるためのモーダル(modal)または比例の割り当てルールを使用して、新しいケースにスコアを付けるための正確な方程式を得ることもできます。
Adv/Syntax add-on【アドオン】第一Choice
結合/離散Choiceデータからの応答は、各Choiceタスク(Choiceセット)からの単一Choiceで構成されます。
潜在クラス(LC)Choiceモデルは、異なる母集団セグメント(潜在クラス)の選択を行う際に異なるChoiceを表現できるようにすることで、異種性を考慮しながらプロファイルデータの分析を行います。
第一Choiceモデルでは、選択多項式ロジットモデル(MNL)を使用して、Choice属性および個々の特性(予測変数)の関数として特定のChoiceを行う確率を推定します。セグメントの記述/予測を改善するために、共変量をモデルに含めることもできます。順位 (MaxDiffを含む)
シーケンシャルロジットモデルは、Choice集合から2つ以上のChoiceが選択されている状況で使用されます。 ここには、1番目と2番目のChoice、1番目と最後のChoice(ベストとワースト)、または他の部分的な順位が、すべての代替の完全な順位と同様に含まれます。レーティングに基づくコンジョイント分析
隣接カテゴリー順序ロジットモデルは、応答データがChoiceではなく格付けで構成される状況で使用されます。割り当てモデル
繰り返しの重みは、回答者がさまざまなChoiceの中から多数の投票(購入、ポイント)を割り当てるデザインを処理するために使用できます。
Choice + Adv/Syntax add-on【アドオン】潜在マルコフ/推移 モジュール
潜在マルコフモデルは、追跡データ変数に対応する標準潜在クラスモデルの拡張です。 実際には、潜在的なクラスタモデルであり、ケースが時間軸に沿ってクラスタ間を移動することが許されます。 潜在マルコフモデルは、潜在推移モデルとも呼ばれています。 Latent GOLDは、クラスごとに異なる遷移確率を持ち、より一般的な混合潜在マルコフモデルを実現します。連続潜在変数(CFactors)
CFactorは、因子分析、項目応答理論モデル、潜在特性モデル、連続ランダム効果を持つ回帰モデルなど、連続潜在変数モデルを指定するために使用できます。 CFactorは、クラスタ、DFactor、または回帰モデルに含めることができますが、CFactor効果に関する追加情報が標準分類、確率平均、モデル分類統計量出力のパラメータ出力とCFactorスコアに表示されます。階層モデル
この高度なオプションは、クラスタ、DFactorまたは回帰モデルへの階層の拡張を指定するために使用され、ケースレベルだけでなくグループレベルでも異質性の説明が可能です。グループレベルの潜在クラス(GClass)および/またはグループレベルのCFactor(GCFactor)を指定することで、グループレベルの変動も考慮に入れることができます。 さらに、2つ以上のGClassが指定された場合、グループレベルの共変量(GCovariates)をモデルに組み込んで、説明/予測を改善することができます。
階層オプションは、3つのレベルパラメトリックまたはノンパラメトリックランダム効果回帰モデルを指定するため、またはグループレベルおよび個別レベルセグメントを同時に開発するためにも使用できます。複雑なサンプルデータに対する調査オプション
2つの重要な調査サンプリング設計は、層別サンプリング – 階層内のサンプリングケース、および2段階クラスタサンプリング – 第1次抽出単位(PSU)内でのサンプリングおよびその後の選択されたPSU内でのケースのサンプリングです。 さらに、サンプリング加重が存在してもかまいません。
調査のオプションは、標準誤差およびパラメータ推定に関連する関連統計を計算する際にサンプリング設計とサンプリング加重を考慮し、「設計効果」を推定します。Syntax モジュール
Syntaxシステムは直観的なコマンド言語であり、グラフィカルユーザーインターフェース(GUI)に柔軟性を提供します。
含まれるオプション
・直観的なLG-Equationsを指定することにより、より柔軟なモデリングとパラメータの制限
・GUIクラスタ、DFactor、回帰、ステップ3、マルコフ、Choiceモジュールと比較した追加モデル
・モンテカルロシミュレーションオプション
・複数の帰属オプション
・N回検証と提供オプション
・追加出力と保存オプション
・保存されたパラメータを使用するためのオプション(スコアリングなど)
Scale Adjusted Latent Class(SALC)models
Choiceモデルに尺度因子を含めることができます。予測値やスケール潜在クラスによって異なる可能性があります。
Scale Adjusted Latent Class(SALC)モデルの2つの重要なアプリケーション
・Choiceモデルの潜在セグメント(クラス)に加えられる尺度クラス(sクラスモデル)が含まれます。
変量リグレット最小(RRM)
・ベストワーストデータ(予測変数オプションを使用)のベストとワーストのChoiceのためのセパレート尺度因子が含まれます。
コーラス(2010年、2012年)は、Random Utility Maximization(RUM)の代わりに変量リグレット最小モデル(RRM)を使用します。
RUMベースのモデルの根底にある行動メカニズムは、個人が最大の効用を有する選択肢を選択するということですが、RRMベースのモデルは、個人が最も小さな潜在的な後悔を有する選択肢を選択すると仮定します。さまざまな分野のRRMアプリケーションを評価した最近の研究では、決定ルール(RUMまたはRRM)がクラスごとに異なる潜在クラスアプローチが、すべてのクラスについて同じ決定ルール(通常はRUM)を仮定したモデルと比較して、モデル適合の大幅な改善につながることを示しています(Chorus、van Cranenburgh、Dekker、2014)。
- 商品詳細
-
動作環境 Windows 7/8.1/10/11(32bit, 64bit)/HD空き容量:120MB以上/RAM:2GB以上
https://its.tos.co.jp/products/latentgold/tech-specs●入力可能なデータ:SPSSシステムファイルや区切り文字で分けられたテキストファイルなど●v5.1 ●全日制の学生向け「スチューデントライセンス(1年ライセンス)」やクラス単位で使用する「クラスルームライセンス(1年ライセンス)」もあり
【インストール条件・購入条件】
●ダウンロード版(ライセンス証書をメールで送信)●永年ライセンス:ライセンス使用期間なし●1年(年間)ライセンス:1年間のみ利用可能●アカデミックライセンス:大学および教育機関で購入可能/アカデミックライセンスは1ユーザーに対して使用を許諾/自宅と学校など、合計3台までのPCにインストール可能(同時起動不可)●スチューデントライセンス(1年ライセンス):全日制の学生向け/申請書に加えて全日制の学生であることの証明書の提出が必要 ●クラスルームライセンス(1年ライセンス):クラス単位で使用/アカデミックライセンスを1セットまたはそれ以上所持している必要あり販売元: スリーワンシステムズ
URL:https://its.tos.co.jp/ - ◆評価版のお申し込みはこちら(メーカーサイト)