Stata 17 日本語/英語版【1年間ライセンス】
データサイエンスに必要なものすべてを含んだソフト
2021年4月20日発売
2022年4月11日価格変更

データ分析・データ管理・グラフ機能・自動レポート機能のすべてを備えた統計分析の統合ソフトです。バージョン17では、表(テーブル)の改良、Pythonとの統合、インタラクティブな計算や開発のためのWebアプリ「Jupyter Notebook」、ベイジアン計量経済学分析など多くの機能が追加されたうえ、計算処理速度が以前よりも更に早くなりました。

価格は予告なく変更される場合があります。
インストール条件については、各ソフトウェアの利用許諾書を必ずご覧ください。
![]() マークが付いている商品のご注文はWEBからは出来ません。詳しくはこちらをご覧ください。
マークが付いている商品のご注文はWEBからは出来ません。詳しくはこちらをご覧ください。
- 製品特徴
Stataが選ばれる理由
速い。正確。使いやすい。
Stataは、データ操作および可視化機能、統計機能、自動レポート機能など、データサイエンスに必要なものすべてを含んだ完全な統合ソフトウェアパッケージです。
基本統計から線形モデル、ノンパラメトリック分析、時系列分析など、幅広い範囲の統計量の計算が可能です。医学の研究者、生物統計学者、免疫学者、エコノミスト、社会学者、政治学者、地理学者、心理学者など、データを分析する必要がある研究専門家向け製品として定評があります。・優れたデータ管理機能であらゆるデータの処理が可能(多種多様なデータ形式をサポート)
・幅広い統計機能
・出版品質のグラフィック
・動的なドキュメント作成
・完全に再現可能な研究
・PyStata-Python統合
・リアルなドキュメント作成
・高い信頼度
・使い易さ
・習得し易さ・自動化が容易
・拡張が容易
・高度なプログラミング
・自動マルチコアサポート
・コミュニティに寄与する機能
・ワールドクラスの技術サポート
・クロスプラットフォームの互換性
・数多くのユーザーに使用されている実績
・総合的なリソース
・活気に満ちたコミュニティ
・手ごろな価格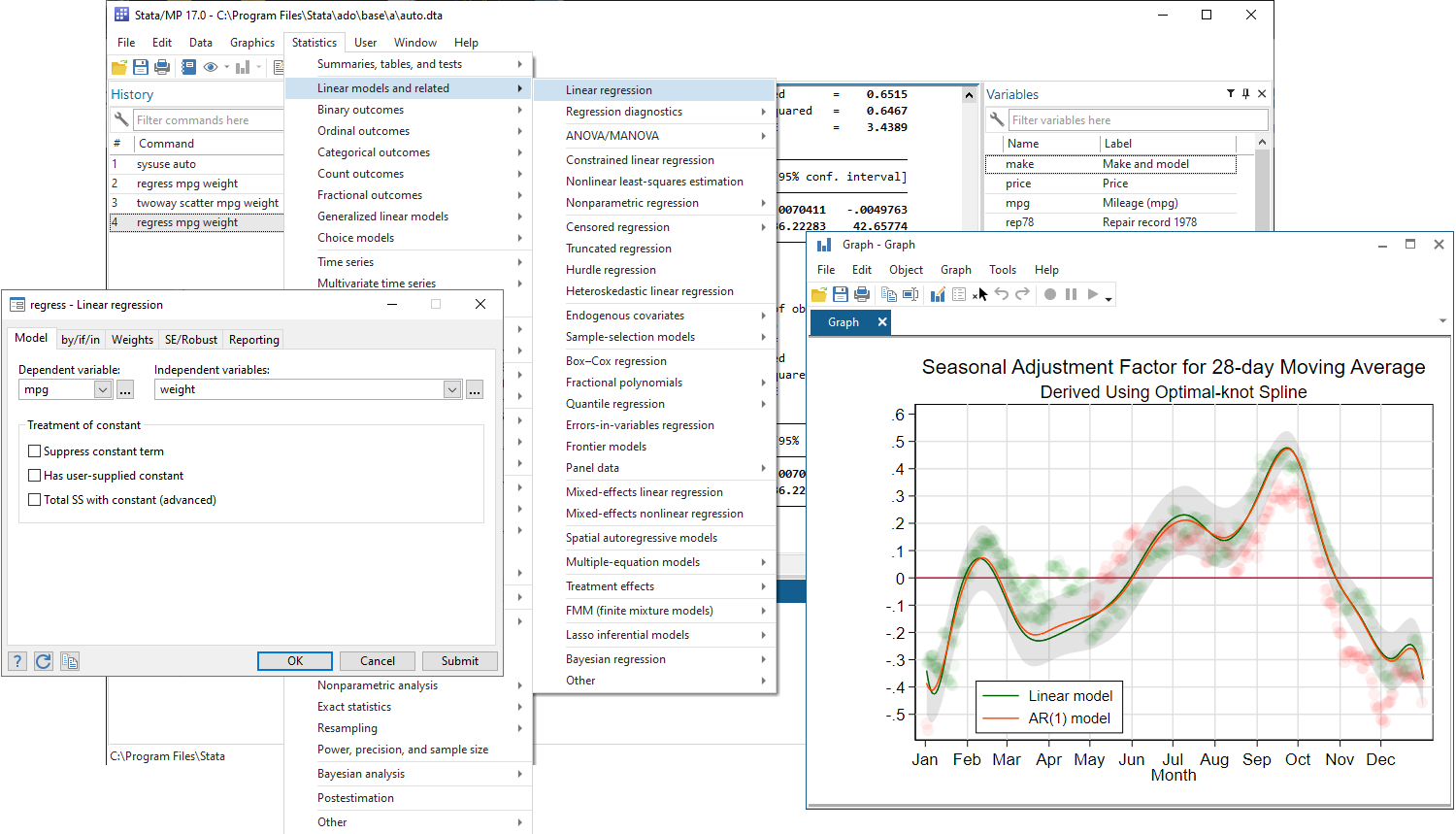
使いやすさ
Stataのすべての機能には、メニュー、ダイアログ、コントロールパネル、データエディタ、変数マネージャ、グラフエディタ、SEMダイアグラムビルダからアクセスできます。どんな分析でもポイントしてクリックすることができます。コマンドやスクリプトを書きたくなければ、そうする必要はありません。
ポイントしてクリックしているときでも、すべての結果を記録して後でそれらをレポートに含めることができます。 アクションによって作成されたコマンドを保存して、後で完全な分析を再現することもできます。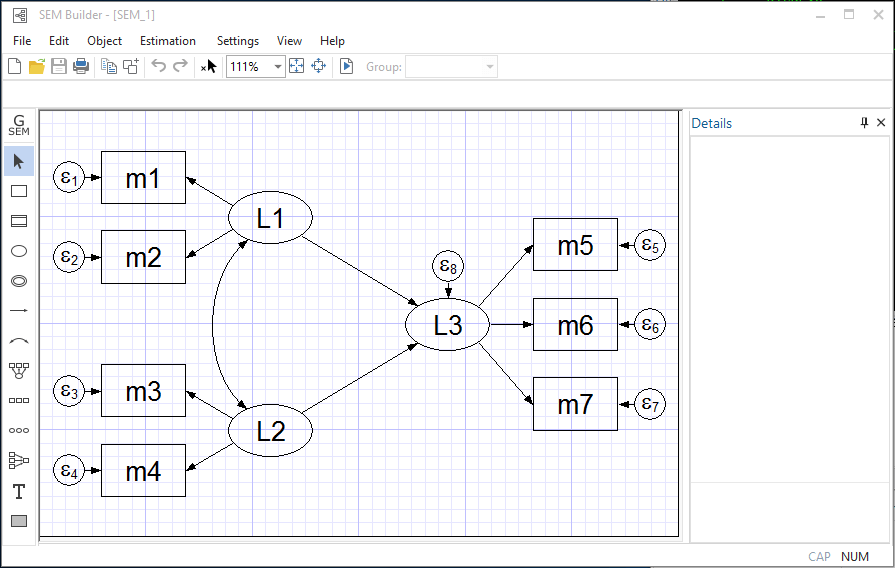
自動化
特定の種類の変数の作成、特定のテーブルの作成、一連の統計手順の実行、RMSEの計算など、すべての人が常に実行するタスクがあります。Stataには何千もの組み込み手順がありますが、比較的ユニークなタスクや特定の方法で実行したいタスクがあるかもしれません。特定のデータセットに対してタスクを実行するスクリプトを作成した場合は、そのスクリプトをすべてのデータセット、変数のセット、および観測のセットで使用できるものに簡単に変換できます。
習得しやすさ
タスクを実行するためのStataのコマンドは直感的で習得が容易です。さらに、タスクの実行について学んだことは、すべて他のタスクに適用することができます。例えば、分析をサンプル内の女性に限定するには、if gender == "female"を任意のコマンドに追加するだけです。vce(robust)を任意の推定量に追加するだけで、多くの一般的な仮定に対してロバストな標準誤差と仮説検定を取得できます。
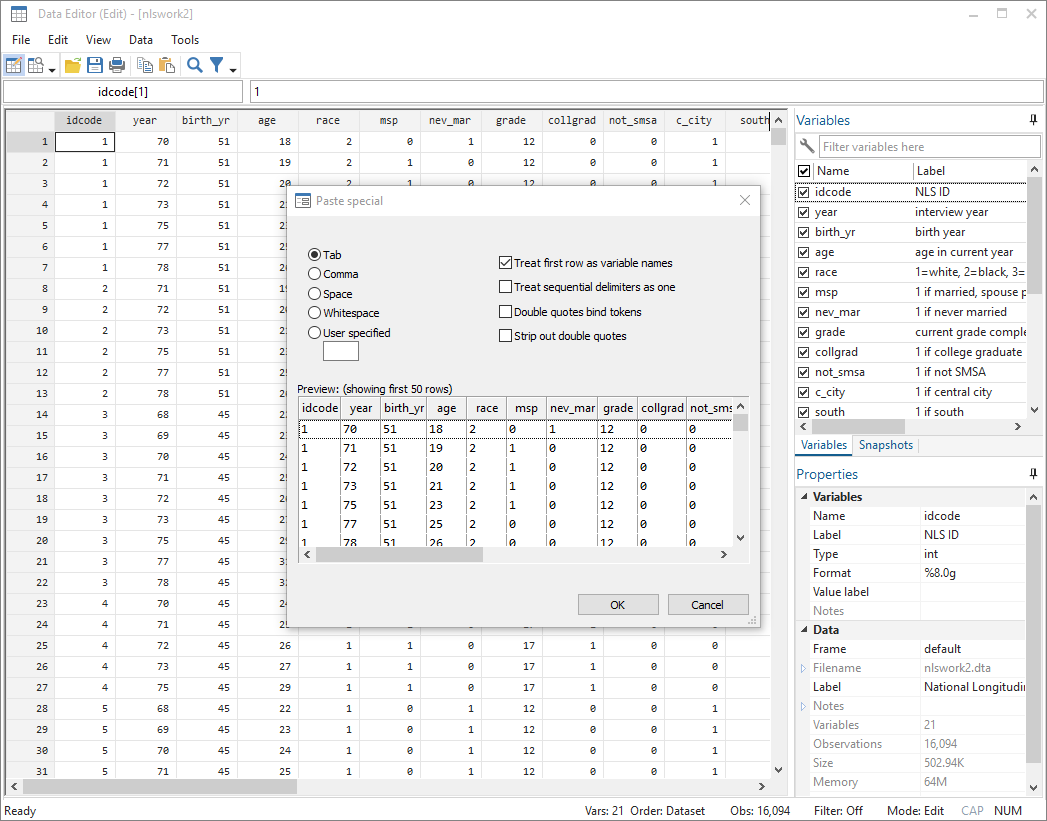
優れたデータ管理機能
・Frames—manage multiple datasets simultaneously
・Import, export
・JDBC, ODBC, SQL
・Sort, match, merge, join, append, create
・Built-in spreadsheet
・Unicode
・Process text or binary data
・Access data locally or on the web
・Collect statistics across groups
・BLOBs—strings that can hold entire documents ほか
出版品質のグラフィック
パブリケーション品質の明確なスタイルのグラフを簡単に生成できます。
ポイントしてクリックすると、カスタムグラフを作成できます。また、再現可能な方法で数百または数千のグラフを作成するスクリプトを作成することもできます。 グラフを公開用にEPSまたはTIFFに、Web用にPNGまたはSVGに、または表示用にPDFにエクスポートします。 統合されたグラフエディタを使用すると、クリックしてグラフに関する情報を変更したり、タイトル、メモ、線、矢印、テキストを追加したりできます。
Stataの主な統計機能
・Case-control分析
・ARIMA
・ANOVA / MANOVA
・線形回帰
・一般化線形モデル(GLM)
・クラスター分析
・対照と比較
・パワー分析
・サンプル選択
・多重モデル
・脆弱性を含む生存モデル・DPD(Dynamic panel data)回帰
・共分散構造分析(SEM)
・2値、カウント、生存アウトカム
・ARCH
・多重代入法
・サーベイデータ
・処置効果
・正確統計
・ベイズ分析
» その他の統計機能はこちら(メーカーサイト)【Stata 17のインターフェースについて(英語)】
主なStata 17の新機能
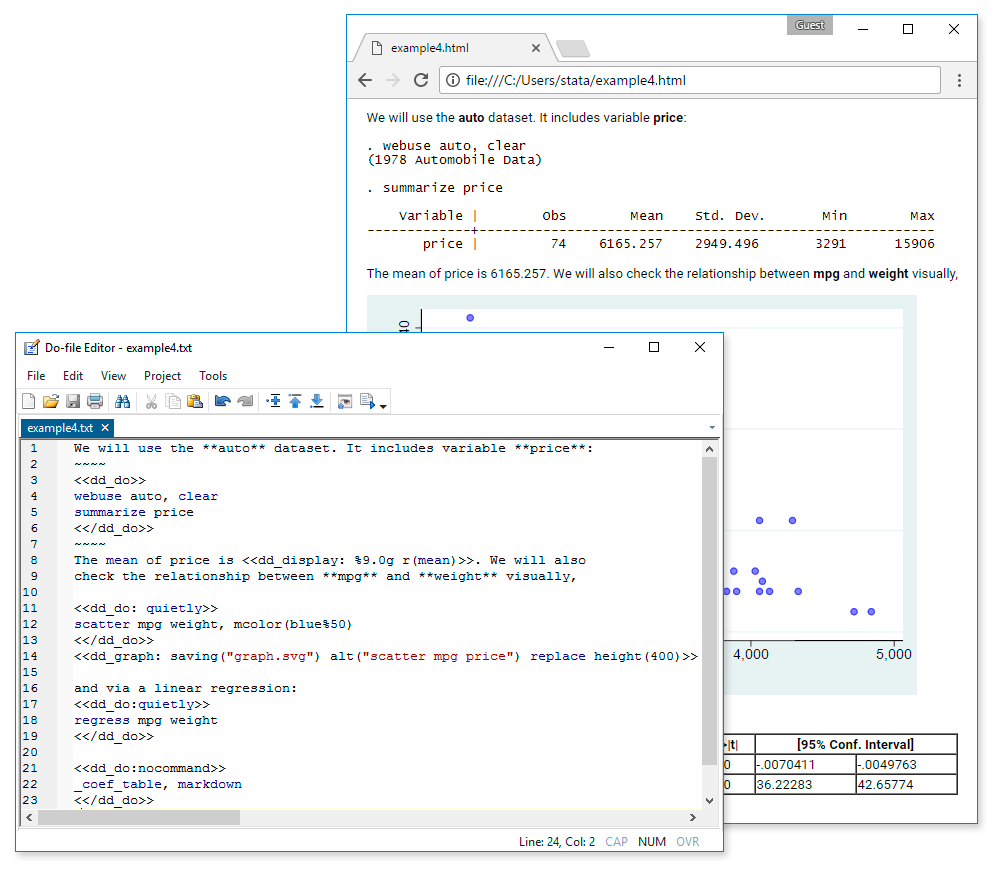
表の改良
回帰結果や要約統計量を比較表を簡単に作成したり、表にスタイルを適用したり、表をMS Word、PDF、HTML、LaTeX、MS Excel、およびMarkdownにエクスポートしてレポートに含めることができます。
tableコマンドが改良されました。
新しい collectプレフィックスは、必要な複数のコマンドから結果を収集し、表を作成し、それらをさまざまな形式にエクスポートします。また、新しいTables Builderを使用してポイント&クリックで表を作成することもできます。処理速度の向上
Stataは精度および速度を重視しています。
精度と速度の間にはしばしばトレードオフがありますが、Stataはユーザーに両方の長所を提供するように努めています。 Stata17では、コマンドを高速化するためにSortとCollapseの背後にあるアルゴリズムを更新しました。
また、マルチレベルのmixed-effectsモデルにフィットする一部の推定コマンドの速度が向上しました。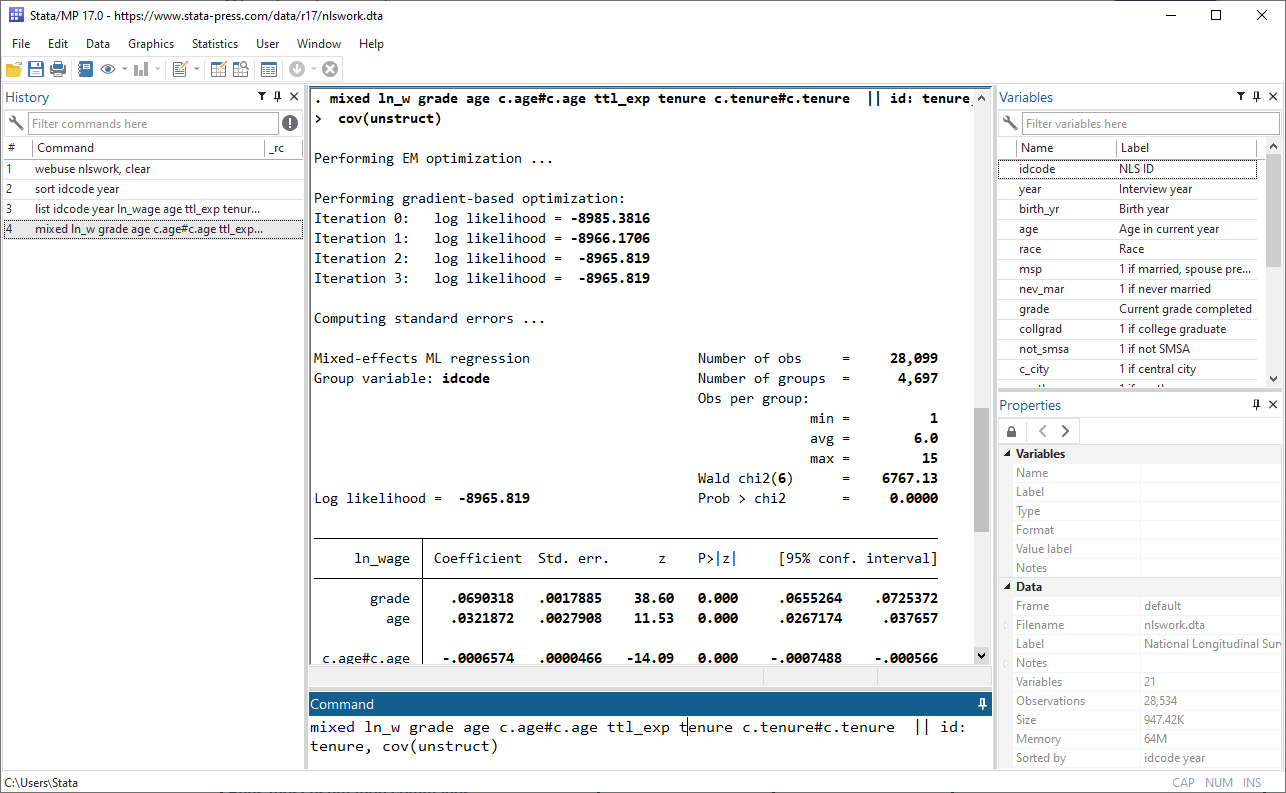
lassoを使用した治療効果の推定
・teffectsを使用することで、治療効果を推定します。
・lassoを使用することで、数百、数千以上の共変量を制御します。
・telassoの使用により、これからは非常に多くの共変量の治療効果と制御を推定できます。PyStata—Python and Stata
Stata 17では、PyStataと呼ばれる概念が導入されました。 PyStataは、StataとPythonが相互作用するすべての方法を含む用語です。 Stata 16はStataからPythonコードを呼び出す機能を備えていましたが、Stata 17では、新しいPystata Pythonパッケージを介してスタンドアロンのPython環境からStataを呼び出し可能にすることで、機能を大幅に拡張しました。
IPythonカーネルベースの環境(例:Jupyter NotebookとコンソールおよびJupyter Labとコンソール)、 IPythonカーネルをサポートする他の環境(例:Spyder IDEやPyCharm IDE)、 または、コマンドラインからのPythonへのアクセス(例:Windowsコマンドプロンプト、macOSターミナル、Unixターミナル、PythonのIDLE)で、StataとMataに簡単にアクセスできます。Difference-in-differences(DID)とDDDモデル
新しい推定コマンドdidregressおよびxtdidregressは、difference-in-differences(DID)および difference-in-difference-in-differences 若しくは triple-differences(DDD)モデルを反復測定データにフィットさせます。 didregressは反復断面データで、xtdidregressは縦断的/パネルデータで機能します。
DIDおよびDDDモデルは、反復測定データを使用して処理済み(ATET)に対する平均処理効果を推定するために使用されます。治療効果の場合は血圧に対する薬物療法の効果に、また、雇用に対するトレーニングプログラムの効果などが考えられます。
既存のteffectsコマンドで使用できる標準の断面分析とは異なり、DID分析では、グループが反復測定を識別するATETを推定するときにグループと時間の効果を制御します。
DDD分析では、追加のグループ効果とそれらの時間との相互作用を制御し、最大3つのグループ変数または2つのグループ変数と1つの時間変数を指定できます。
◆さらに詳しく https://www.stata.com/new-in-stata/
*取扱えるデータ量は実装メモリの容量により制限されます。パッケージ Stata/BE Stata/SE Stata/MP 変数(列)の上限 2,048 32,767 120,000 観測データ(行)の上限 21億4千万 21億4千万 200億以上 独立変数の上限 798 10,998 65,532 並列処理 不可 不可 可 サポートコア数 1コア 1コア 2コア/4コア +
特にStata MPについては、現在この観測データ上限数を賄えるメモリを備えたコンピュータがほとんど市販されていないため、
取扱えるデータ量はメモリの容量の限界までとなります。
【コンピュータの能力を最大限に活かすおすすめ製品】
※ さらに多くのCPU搭載マシンでのご利用には、Stata/MP6、Stata/MP8などもございます。別途お問い合わせください。Stata/SE 1CPU搭載コンピュータ Stata/MP2 2CPU(またはDuo-Core、Double-Core)搭載コンピュータ Stata/MP4 4CPU(またはQuad-Core)搭載コンピュータ
- 商品詳細
-
動作環境 《Win》IntelまたはAMD x86-64プロセッサ/Windows Server 2012R2/Server 2016/Server 2019/Server 2022/Windows 8.1/10/11(64bit)
《Mac》Apple SiliconまたはIntelプロセッサ/Apple Silicon:macOS 11.0以上/Intelプロセッサ:macOS 10.12以上(64bit)
《Linux》x86-64またはその互換プロセッサ/Linux OS(64bit)
※xstata には GTK 2.24 が必要
[全OS共通]HD空き容量:2GB以上/RAM:BE 1GB以上、SE 2GB以上、MP 4GB以上
※動作環境の詳細:https://www.stata.com/products/compatible-operating-systems/●メニューやダイアログを日本語で表示する日本語インターフェース搭載(インストール時、またはインストール後に切り替え)●UNICODEに対応し、日本語の利用可能●【分析可能なDatasets】Stata/MP:最大120,000の変数/Stata/SE:最大32,767の変数/Stata/BE:最大2,048の変数●線形および一般化線形モデル(GLM)、回帰機能(回数/バイナリ結果)、クラスタ分析、多層混合モデル(multilevel mixed models)やARCHなど、統計解析に関する高度な機能から標準的なものまで、数百にも及ぶ機能搭載●回帰フィット、分散プロット、時系列グラフ、生存プロット等のグラフを容易に作成●データセットの結合や構成変更、変数の管理、グループや反復をまたいだ統計量の集計等●操作対象のデータタイプ:バイト、整数、長整数(long)、浮動小数、倍精度小数(double)、ストリング●生存/期間データ、時系列データ、パネル/縦断的(longitudinal)データ、カテゴリカルデータ、調査結果データ等に特化した管理用ツールも用意●新機能や製品アップデートのインストールをインタネットを介して簡単な操作で実行可能●Stata/MPはマルチプロセッサ対応版●ダウンロード版●日本語スタートアップガイド(PDF)付き●利用期限:1年間●シングルユーザライセンス
【インストール条件・購入条件】
●1ライセンスにつき、登録ユーザのみ使用可能もしくは登録ユーザのみがStataにアクセス可能な複数台のマシンにインストール可能(同時起動および共有不可)●ライセンスは登録ユーザに帰属●購入時に教育機関発行のEメールアドレスが必要●シングルユーザライセンス(同時起動可能なネットワークライセンスもあり)販売元: JUCA, Inc.
URL:https://www.academic-soft.com/ - ◆「Stata 17 日本語/英語版 【永続ライセンス/1年間の無償アップグレード保守付き】」はこちら

日本語PDFスタートアップガイドとは
インストール、基本操作、各種推定コマンドの代表的な用法を記載した、基盤系だけでなく、医療系、計量経済系まで、基本的な一通りの機能を短時間で修得することができる「Math工房」作成の日本語ガイドです。
(1オーダーにつき1ガイド提供されます)
◆特定の大学限定で教職員用特別割引価格が適用される「Prof+ Plan」についてはこちら
