Text Mining Studio/Alkano



日本語の分かち書き機能と豊富な分析機能を備えたテキストマイニングツールです。論文や医療看護記録、実習記録、アンケート、インタビューデータ、SNSログなどの大量のテキストデータを分析できます。テキストマイニングの第一歩である頻度分析から、テキストに付随する属性を活かした特徴分析、話題分析など豊富な機能を備え、更に結果をグラフィカルに表現できます。

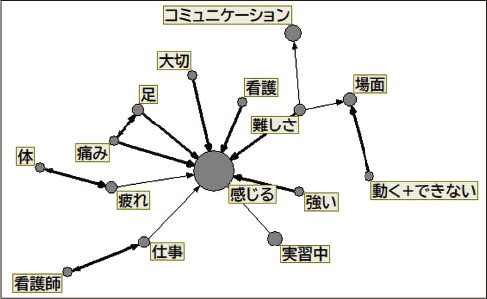
言葉や属性のネットワーク図を作成できます。共起関係や係り受け関係を抽出して、ことば同士の関連性を分析し、テキスト中にどのような話題が存在するのか把握できます。クラスタ数の変更も行えます。

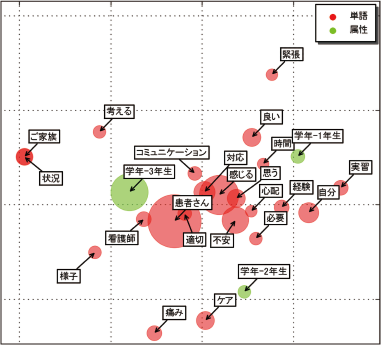
ことばと属性の関係を2次元にマッピングできます。各属性表現方法や話題の紐づき方を直感的に理解できます。

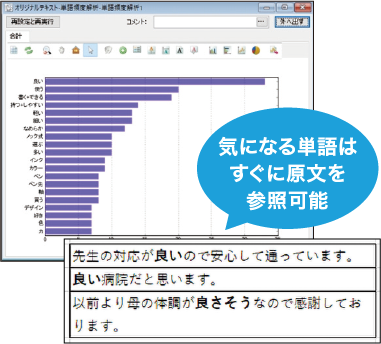
テキスト全体から単語の出現頻度を一覧表示します。テキストの概要を把握し、他の分析への指針とする基本分析です。

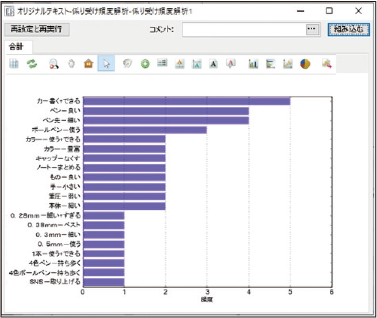
単語同士の意味的なつながり=「係り受け表現」を抽出します。文章構造からより具体的な内容を把握する分析です。

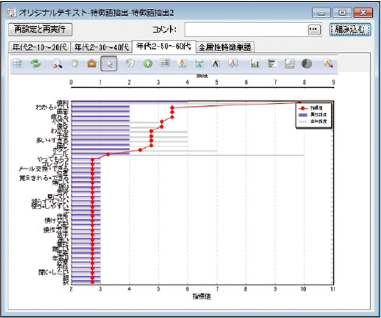
ある統計量の基で、属性毎に特徴的に出現する「係り受け表現」を抽出し、属性毎の差異から傾向を明らかにします。


データ取り込みから前処理、可視化、モデリング、運用まで一連の分析プロセスを直感的なGUI操作で実行可能です。数値データだけでなく、報告書・アンケート・議事録など自由記述のテキスト処理も行えます。処理したデータを活用して、文脈を考慮した高度な文書分類モデルなどを構築できます。数値データとテキストデータを組み合わせることでより多面的な分析を行えます。

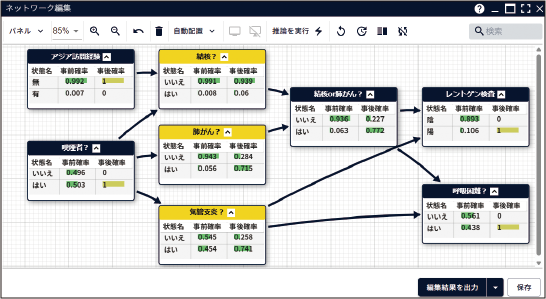
"複雑な現象のつながり” を、
確率で理解する
1つの要因を変えるだけで、他の事象の確率がどう変化するかを即座に可視化します。ベイジアンネットワークを用いて複雑な確率的因果関係を直感的にシミュレーションできます。

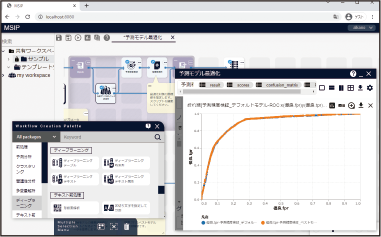
ディープラーニングの機能をマウス操作で利用できます。テーブルデータ、時系列データ、テキストデータ、テキスト+属性データの4つの入力データのパターンに対し、ディープラーニングによるモデリングや予測を実行できます。

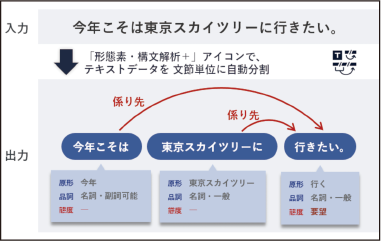
単語と単語の意味的つながりやニュアンスを推定して文章を文節単位に区切る「形態素・構文解析+」、長さや頻度から語を絞り込む「語句のフィルタリング」、「ルールベース文書ラベル付与」など、テキスト分析も多くの機能があります。

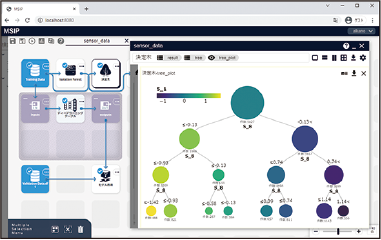
教師値付の学習データが存在する場合、「予測」や「分類」といったタスクを実行できます。線形回帰、ロジスティック回帰、Elastic Net、決定木、ランダムフォレスト、ニューラルネットワーク等、機械学習のアルゴリズムを実行できます。

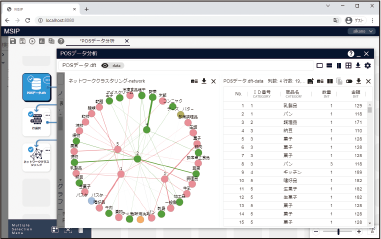
教師値が存在しない場合も、データの特徴抽出やクラスタリングを実行できます。多変量解析、k-means法、One Class SVM、Isolation Forest、アソシエーション分析等、さまざまな機械学習のアルゴリズムを実行できます。

価格は予告なく変更される場合があります。
インストール条件については、各ソフトウェアの利用許諾書を必ずご覧ください。
![]() マークが付いている商品のご注文はWEBからは出来ません。詳しくはこちらをご覧ください。
マークが付いている商品のご注文はWEBからは出来ません。詳しくはこちらをご覧ください。
